Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習 - pandas入門
Search
Y. Yamamoto
March 24, 2025
Science
0
6
機械学習 - pandas入門
Y. Yamamoto
March 24, 2025
Tweet
Share
More Decks by Y. Yamamoto
See All by Y. Yamamoto
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
0
640
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
0
610
データベース10: 拡張実体関連モデル
trycycle
0
630
データベース09: 実体関連モデル上の一貫性制約
trycycle
0
610
データベース08: 実体関連モデルとは?
trycycle
0
590
データベース14: B+木 & ハッシュ索引
trycycle
0
290
データベース15: ビッグデータ時代のデータベース
trycycle
0
240
データベース06: SQL (3/3) 副問い合わせ
trycycle
0
430
データベース05: SQL(2/3) 結合質問
trycycle
0
550
Other Decks in Science
See All in Science
小杉考司(専修大学)
kosugitti
2
630
Explanatory material
yuki1986
0
130
04_石井クンツ昌子_お茶の水女子大学理事_副学長_D_I社会実現へ向けて.pdf
sip3ristex
0
250
応用心理学Ⅰテキストマイニング講義資料講義編(2024年度)
satocos135
0
120
統計的因果探索: 背景知識とデータにより因果仮説を探索する
sshimizu2006
3
750
【健康&筋肉と生産性向上の関連性】 【Google Cloudを企業で運用する際の知識】 をお届け
yasumuusan
0
500
FOGBoston2024
lcolladotor
0
170
Causal discovery based on non-Gaussianity and nonlinearity
sshimizu2006
0
240
Snowflakeによる統合バイオインフォマティクス
ktatsuya
0
630
白金鉱業Meetup Vol.16_【初学者向け発表】 数理最適化のはじめの一歩 〜身近な問題で学ぶ最適化の面白さ〜
brainpadpr
10
2k
240510 COGNAC LabChat
kazh
0
190
統計学入門講座 第1回スライド
techmathproject
0
260
Featured
See All Featured
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
227
22k
How STYLIGHT went responsive
nonsquared
99
5.4k
Fontdeck: Realign not Redesign
paulrobertlloyd
83
5.4k
Building an army of robots
kneath
304
45k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
8
690
Being A Developer After 40
akosma
89
590k
Optimising Largest Contentful Paint
csswizardry
34
3.1k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
129
19k
YesSQL, Process and Tooling at Scale
rocio
172
14k
Building Applications with DynamoDB
mza
94
6.3k
The Illustrated Children's Guide to Kubernetes
chrisshort
48
49k
Why You Should Never Use an ORM
jnunemaker
PRO
55
9.3k
Transcript
pandas入門 ⼭本 祐輔 名古屋市⽴⼤学 データサイエンス研究科
[email protected]
第2回 機械学習発展(導入編) ⼭本祐輔 クリエイティブコモンズライセンス
(CC BY-NC-SA 4.0)
1pandasとは?
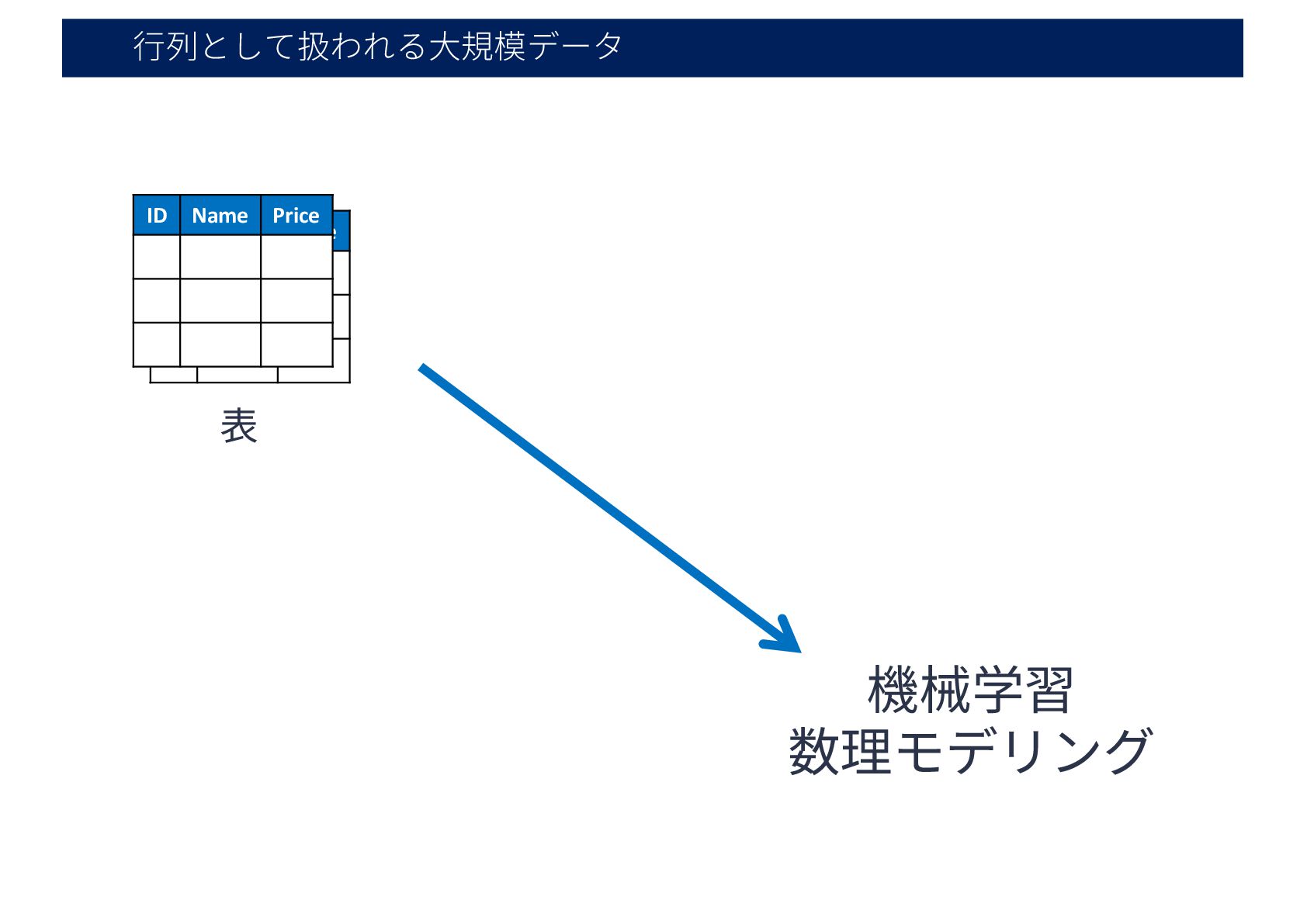
⾏列として扱われる⼤規模データ ID Name Price 表 ID Name Price 機械学習 数理モデリング
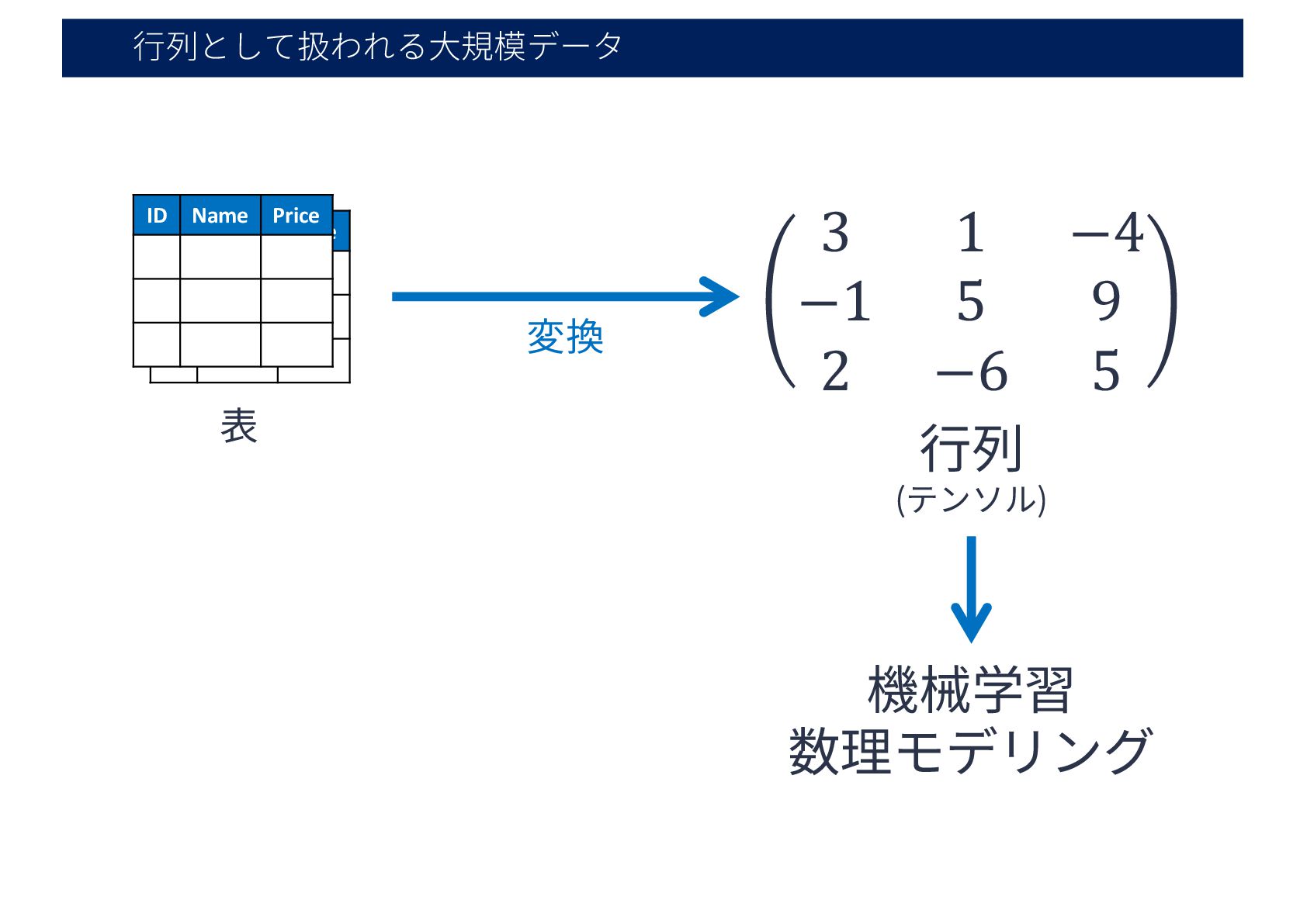
⾏列として扱われる⼤規模データ ID Name Price 表 ID Name Price 機械学習 数理モデリング
⾏列 (テンソル) 3 1 −4 −1 5 9 2 −6 5 変換
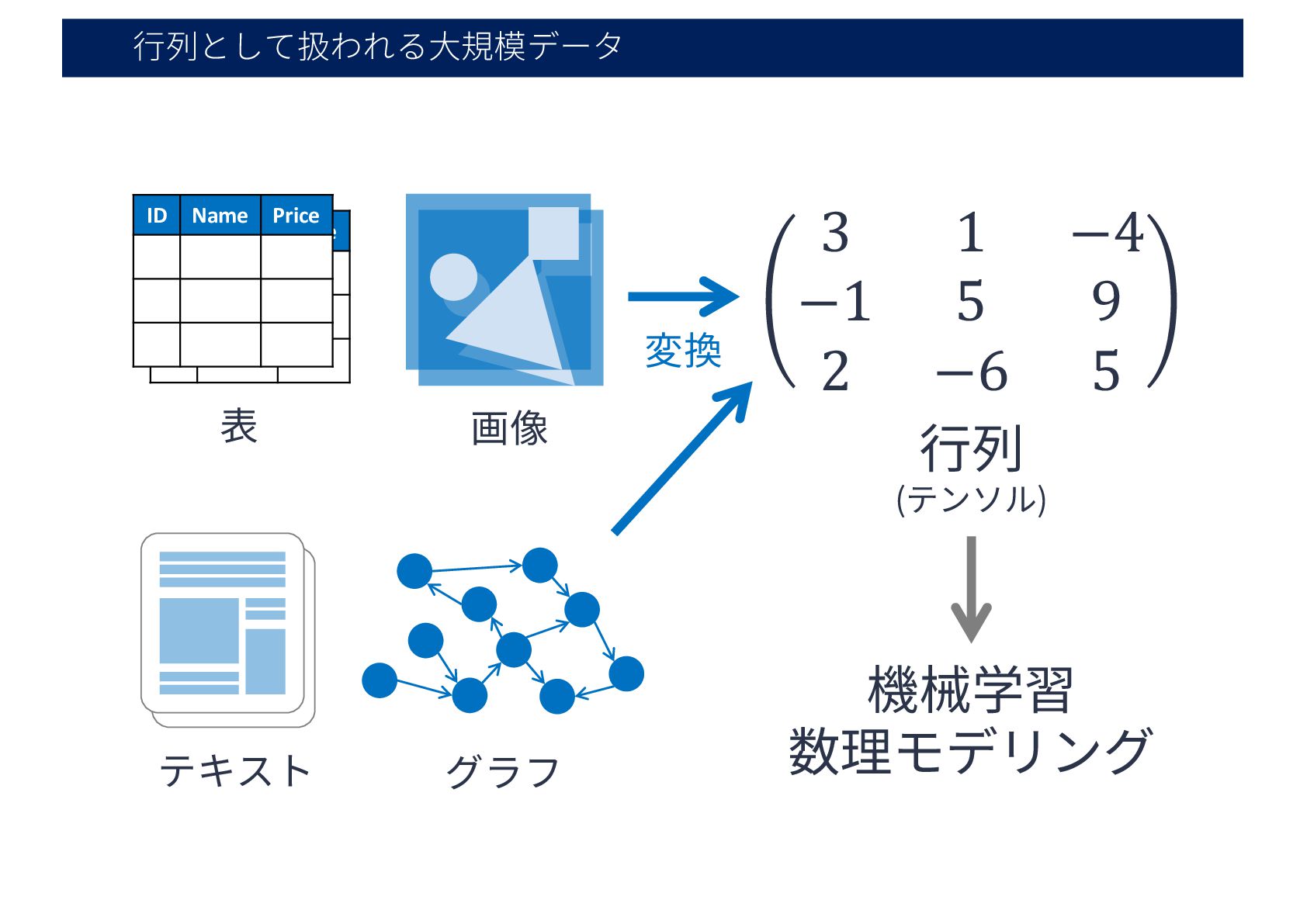
⾏列として扱われる⼤規模データ ID Name Price 表 ID Name Price 機械学習 数理モデリング
グラフ テキスト 画像 ⾏列 (テンソル) 3 1 −4 −1 5 9 2 −6 5 変換
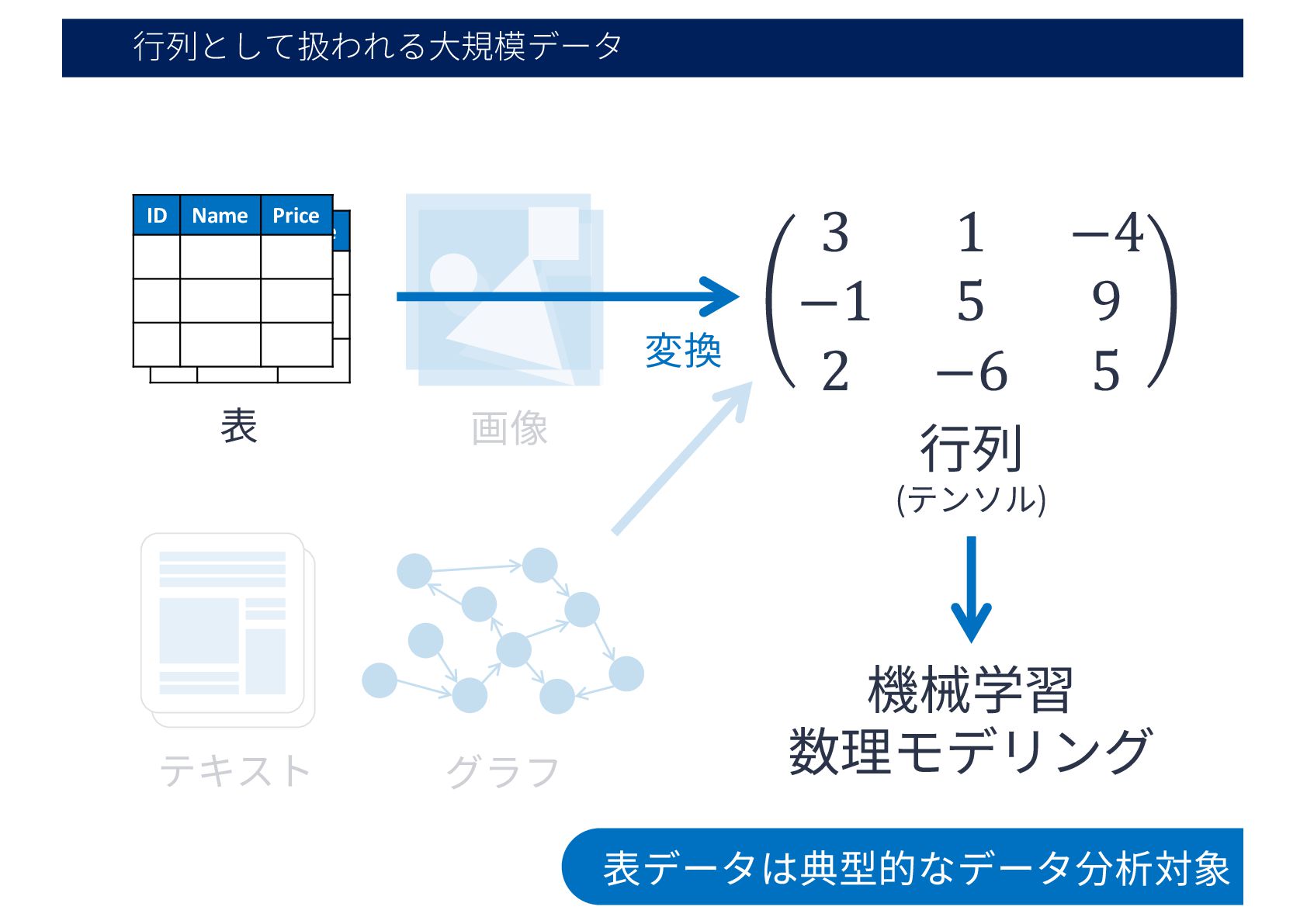
⾏列として扱われる⼤規模データ ID Name Price 表 ID Name Price 機械学習 数理モデリング
グラフ テキスト 画像 ⾏列 (テンソル) 3 1 −4 −1 5 9 2 −6 5 変換 表データは典型的なデータ分析対象
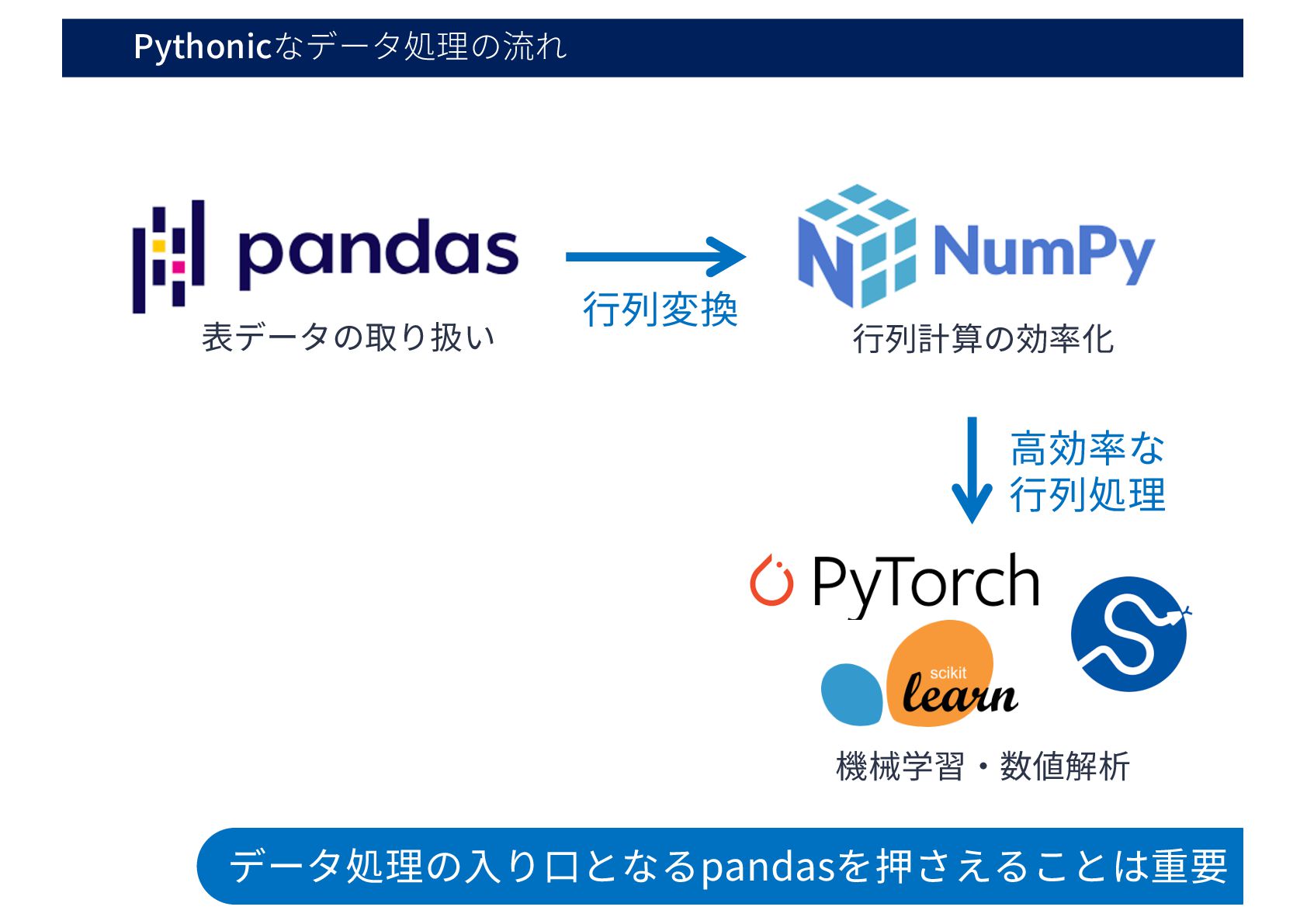
Pythonicなデータ処理の流れ ⾏列変換 ⾼効率な ⾏列処理 データ処理の⼊り⼝となるpandasを押さえることは重要 ⾏列計算の効率化 機械学習・数値解析 表データの取り扱い
pandasとデータフレーム - 表データを効率良く扱うためのPythonライブラリ - データフレームと呼ばれるデータ構造を⽤いて 表データを効率的に処理 データフレーム pandas - 列ごとに型が定義された表データを扱うためのデータ構造
- NumPyの多次元配列(numpy.ndarray)と変換が容易
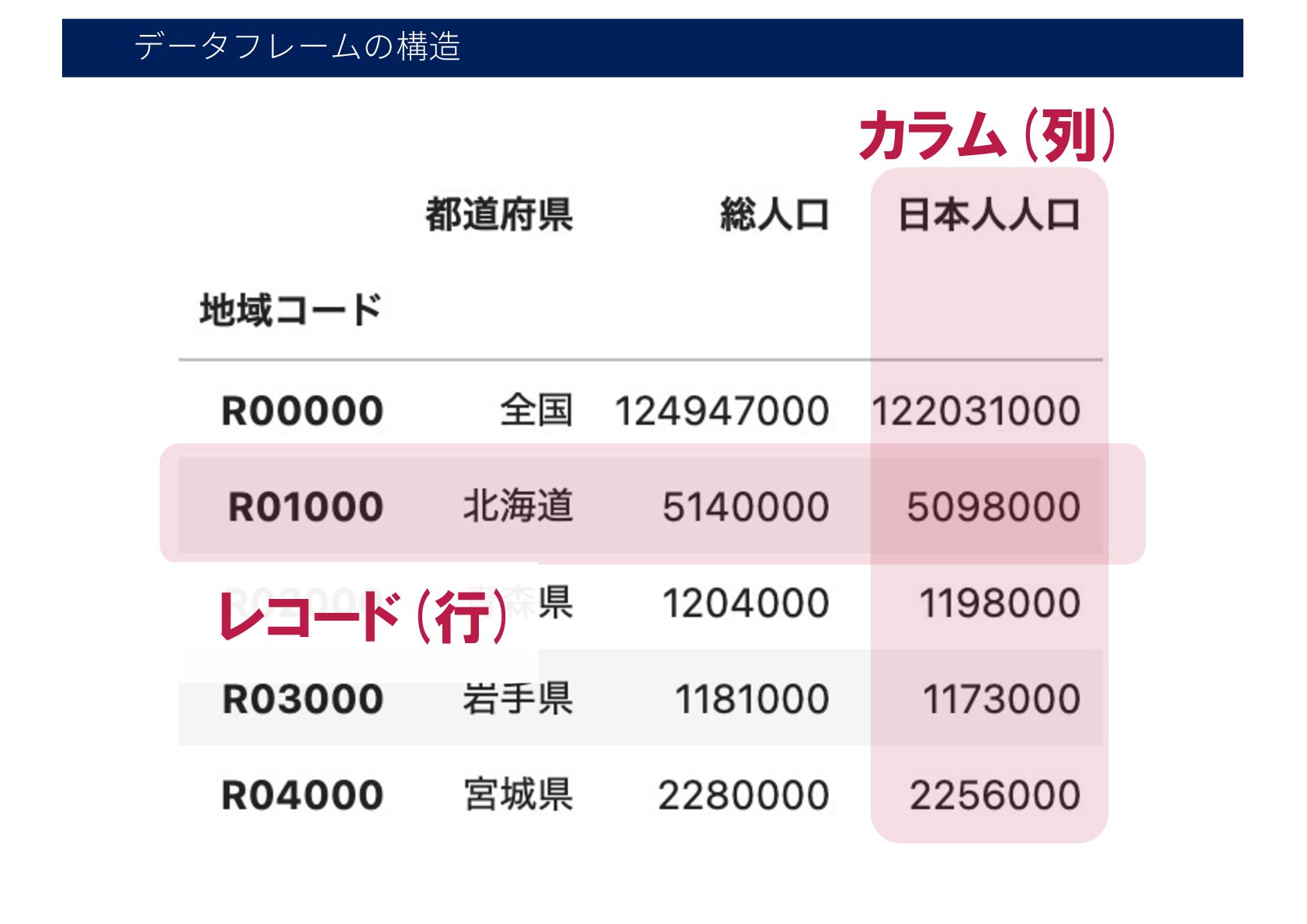
データフレームの構造 レコード(行) カラム(列)
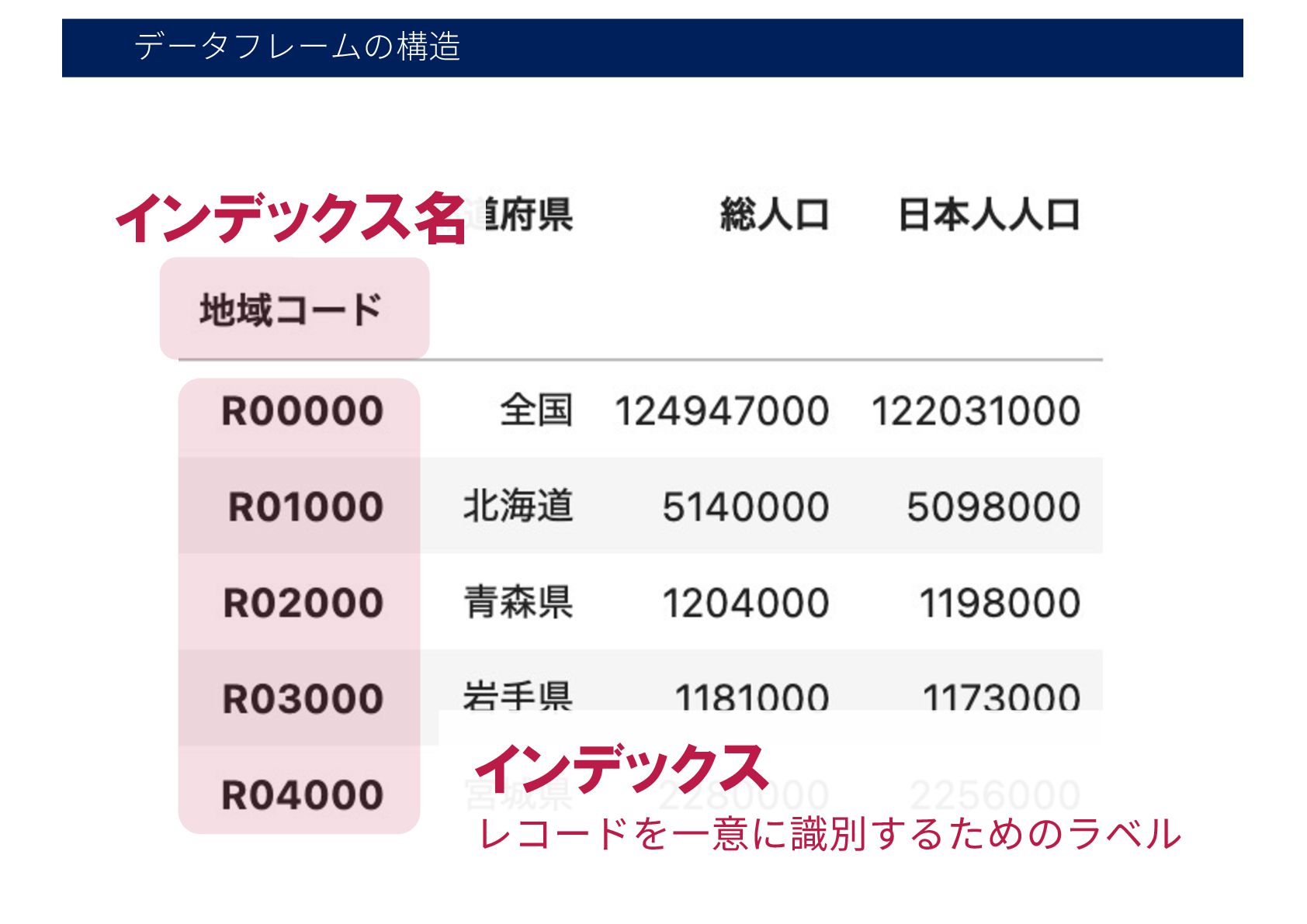
データフレームの構造 インデックス名 インデックス レコードを⼀意に識別するためのラベル
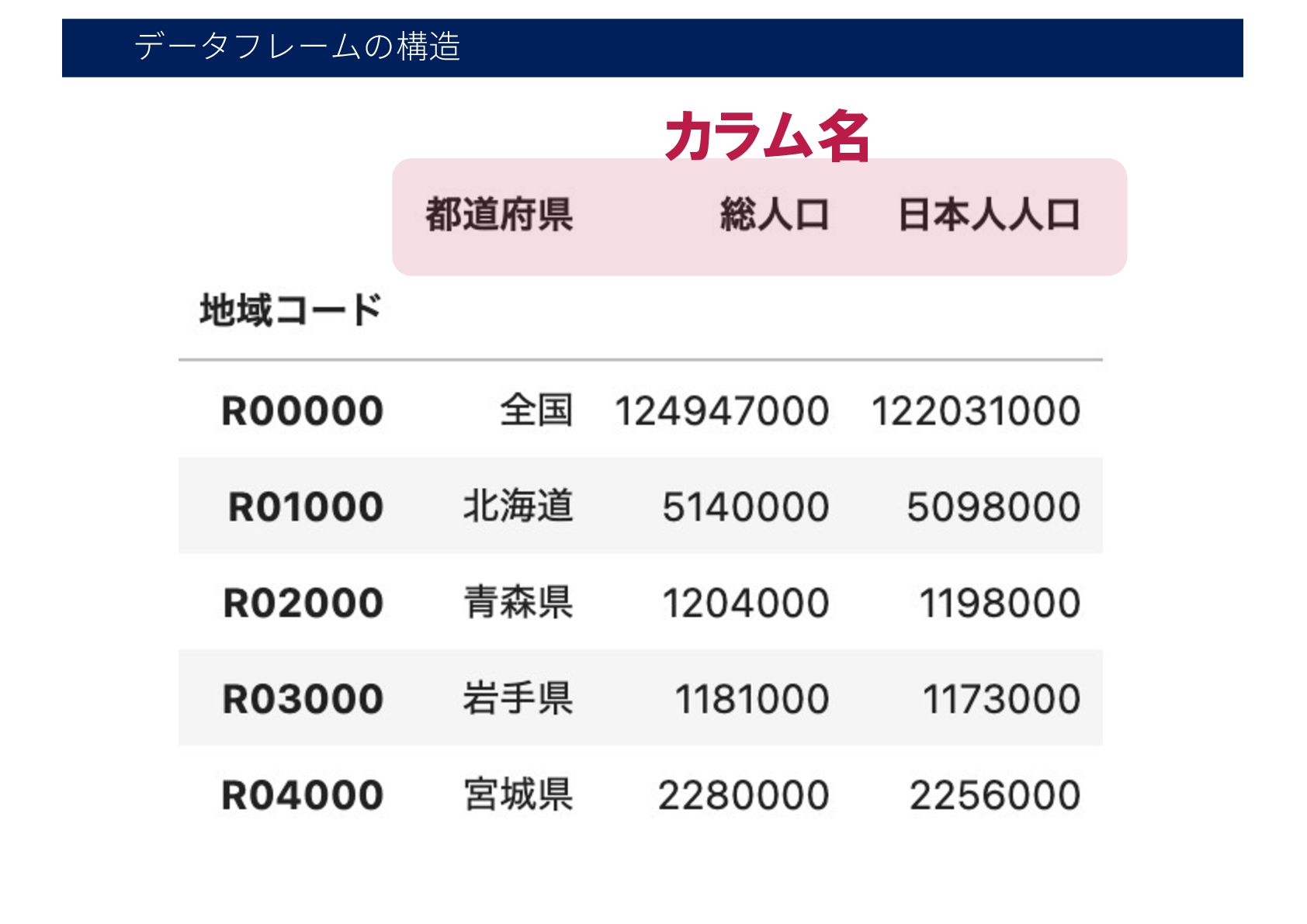
データフレームの構造 カラム名
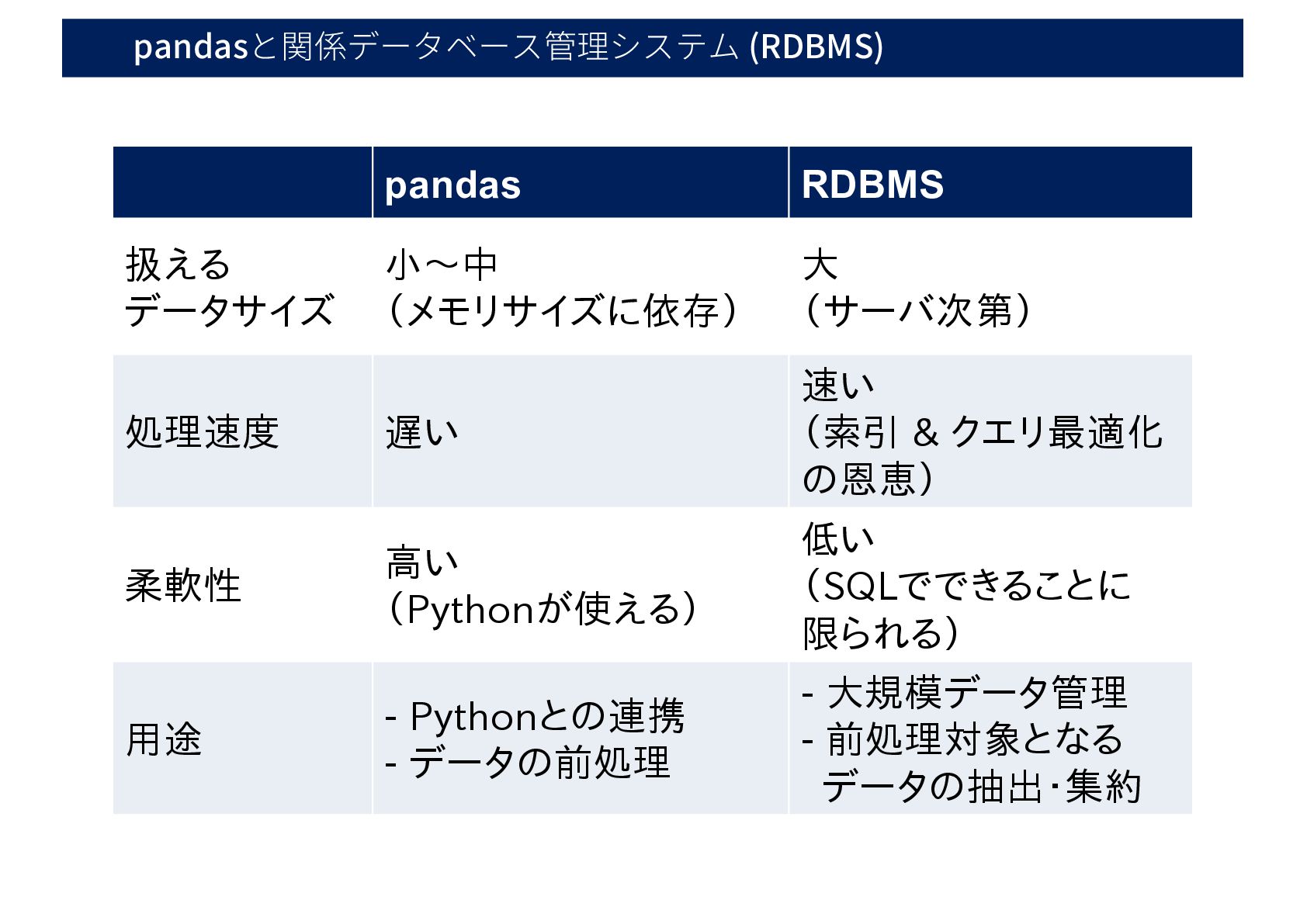
pandasと関係データベース管理システム (RDBMS) pandas RDBMS 扱える データサイズ 小〜中 (メモリサイズに依存) 大 (サーバ次第)
処理速度 遅い 速い (索引 & クエリ最適化 の恩恵) 柔軟性 高い (Pythonが使える) 低い (SQLでできることに 限られる) 用途 - Pythonとの連携 - データの前処理 - 大規模データ管理 - 前処理対象となる データの抽出・集約
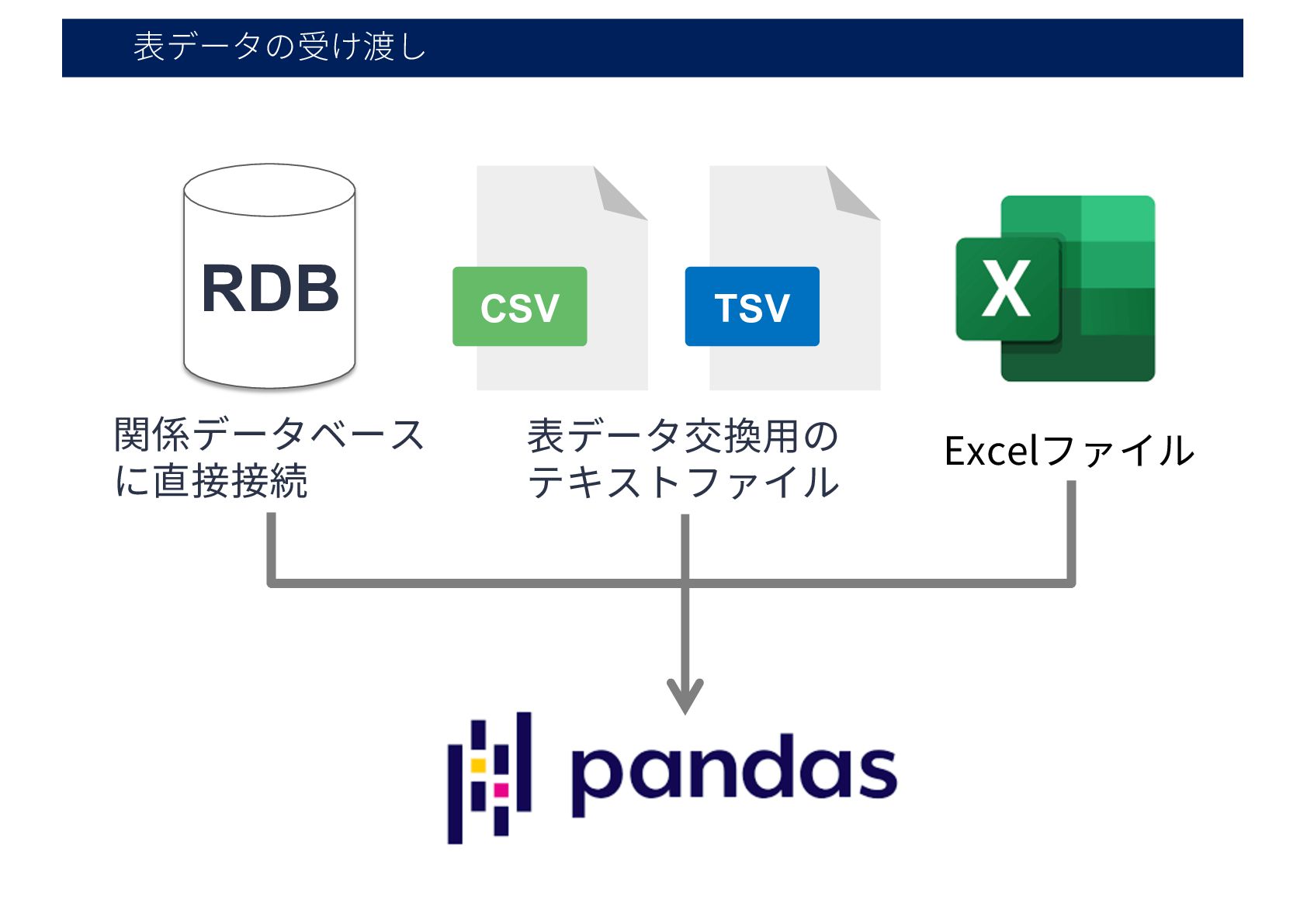
表データの受け渡し CSV TSV RDB 表データ交換⽤の テキストファイル 関係データベース に直接接続 Excelファイル
CSVファイル - 表形式のデータ交換⽤に⽤いられるテキストファイル - CSVファイルの⾏が表の⾏に相当 - 表の各項⽬の値をカンマ(,)で区切る - 1⾏⽬には表の構造を⽰す項⽬名を並べることがある -
CSVファイルの拡張⼦はcsv ID,都道府県,県庁所在地 1,北海道, 札幌市 2,青森県, 青森市 3,岩手県, 盛岡市 ... CSVファイルの中⾝ ID 都道府県 県庁所在地 1 北海道 札幌市 2 青森県 青森市 3 岩手県 盛岡市 … 表データ 解釈
TSVファイル - 表形式のデータ交換⽤に⽤いられるテキストファイル - TSVファイルの⾏が表の⾏に相当 - 表の各項⽬の値をタブ記号(\t: 不可視⽂字)で区切る - 1⾏⽬には表の構造を⽰す項⽬名を並べることがある
- TSVファイルの拡張⼦はtsv ID 都道府県 県庁所在地 1 北海道 札幌市 2 青森県 青森市 3 岩手県 盛岡市 ... TSVファイルの中⾝ ID 都道府県 県庁所在地 1 北海道 札幌市 2 青森県 青森市 3 岩手県 盛岡市 … 表データ 解釈
Hands-on タイム 以下のURLにアクセスして, pandasを使いながら講義を受けよう https://mlnote.hontolab.org/ 17
2 最低限のpandas 18
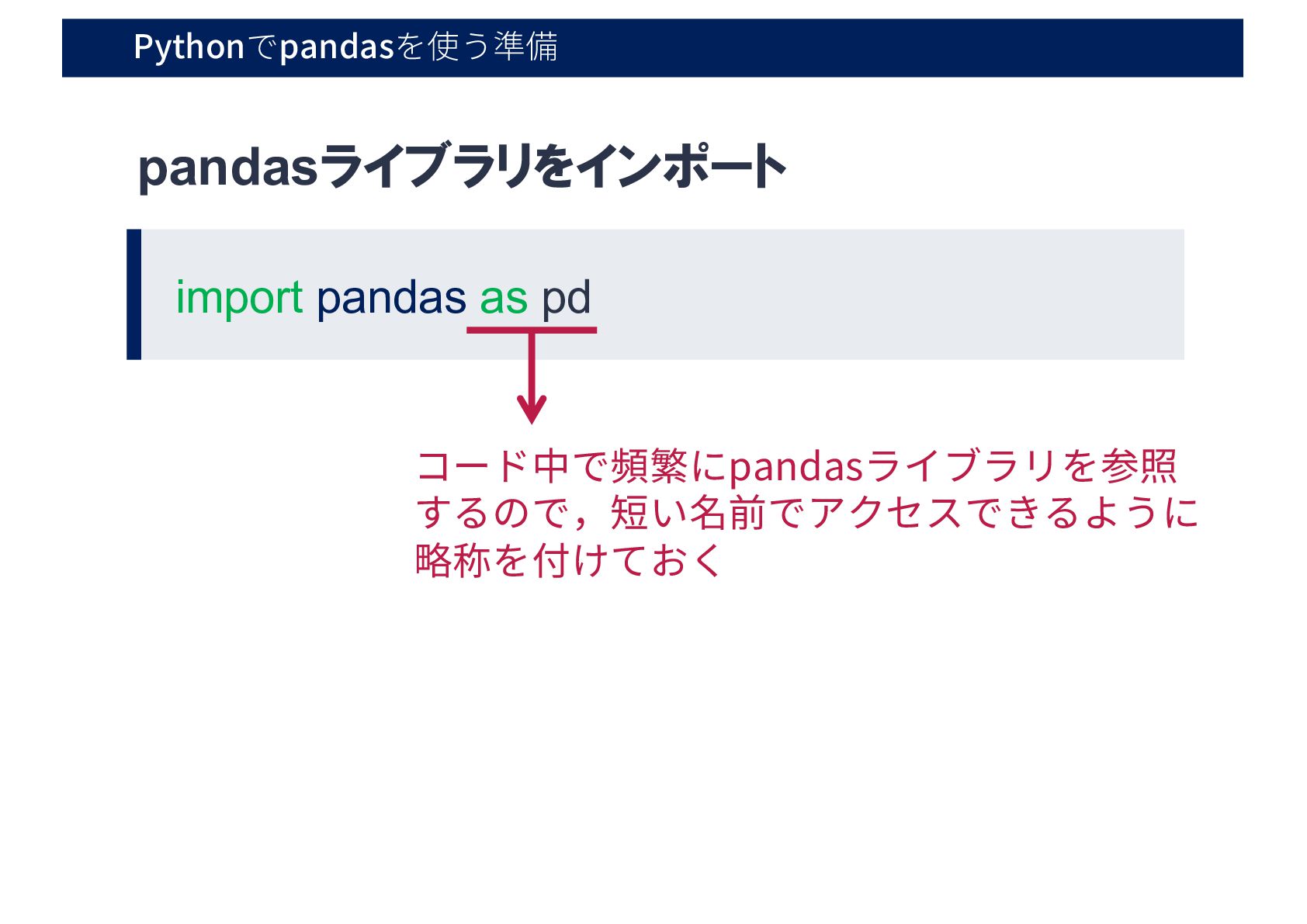
Pythonでpandasを使う準備 import pandas as pd; pandasライブラリをインポート コード中で頻繁にpandasライブラリを参照 するので,短い名前でアクセスできるように 略称を付けておく
CSV/TSVファイルの読み取り df = pd.read_table( “読み込むCSV/TSVファイルの場所 or URL”, sep=‘区切り⽂字’, header=⾒出し⾏の場所, index_col=‘インデックス名’
) pandas.read_table ファイルからデータフレームを読み込むメソッド
CSV/TSVファイルの読み取り – 例 df = pd.read_table( “data/SSDSE-E-2024.csv”, sep=‘,’, header=2, index_col=‘地域コード’
) ← 読み込むファイル ← 区切り⽂字はカンマ ← ⾒出しは2⾏⽬(数え始めはゼロ) ← 「地域コード」列をインデックスに pandas.read_table ファイルからデータフレームを読み込むメソッド
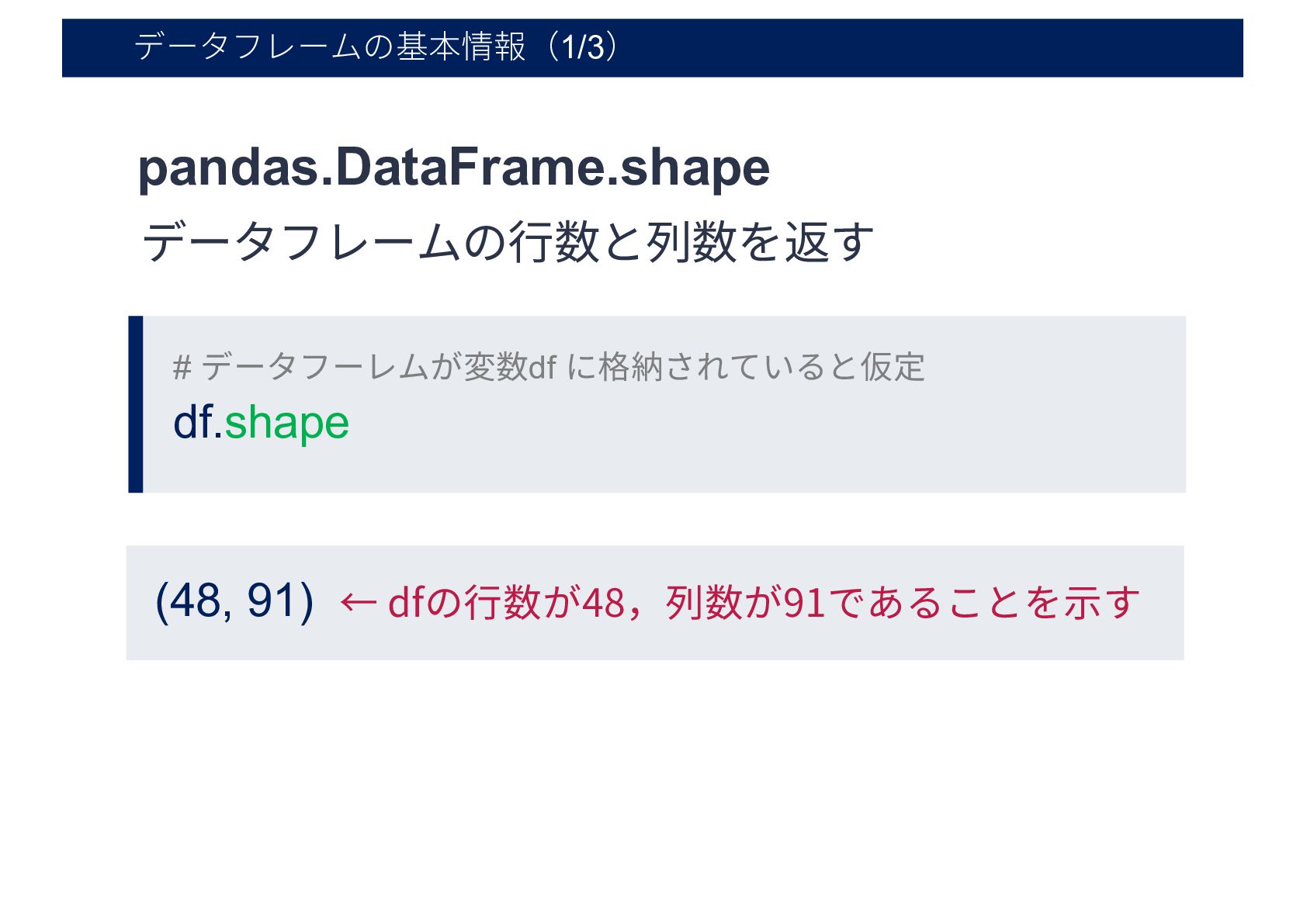
データフレームの基本情報(1/3) # データフーレムが変数df に格納されていると仮定 pandas.DataFrame.shape df.shape (48, 91) データフレームの⾏数と列数を返す ←
dfの⾏数が48,列数が91であることを⽰す
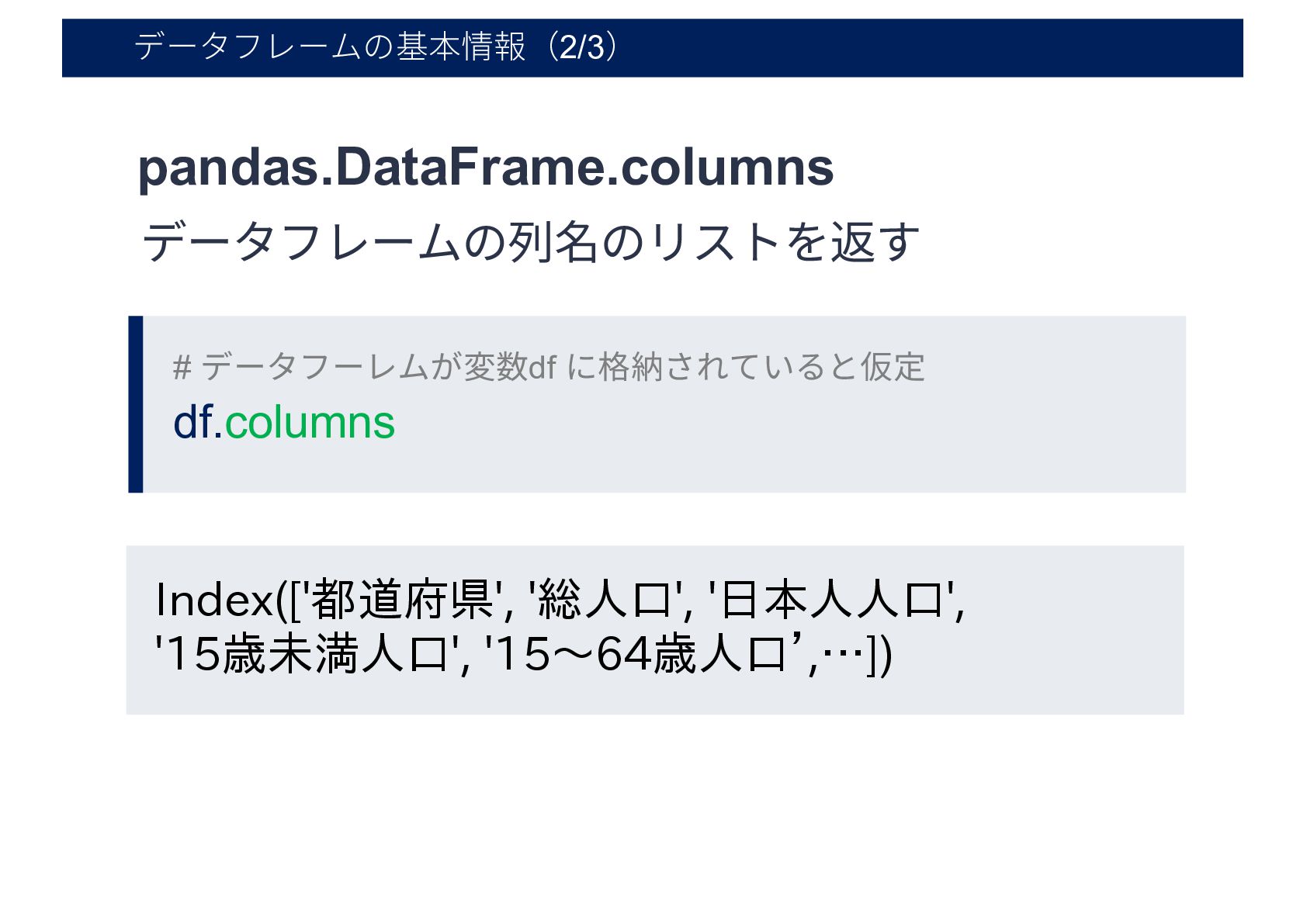
データフレームの基本情報(2/3) # データフーレムが変数df に格納されていると仮定 pandas.DataFrame.columns df.columns Index(['都道府県', '総人口', '日本人人口', '15歳未満人口',
'15〜64歳人口’,…]) データフレームの列名のリストを返す
データフレームの基本情報(3/3) # データフーレムが変数df に格納されていると仮定 pandas.DataFrame.describe df.describe() データフレームの基本統計量を返すメソッド
射影(1/2) # データフーレムが変数df に格納されていると仮定 df.総⼈⼝ 表⽰したい列をドットもしくは中括弧で指定 df[“総⼈⼝”]
射影(2/2) # データフーレムが変数df に格納されていると仮定 中括弧で列名リストを指定すると複数列を射影 df[“都道府県”, “総⼈⼝”]
データフレーム × 四則演算(1/2) # 各⾏の総⼈⼝の値に100を加算 射影した列にスカラーの四則演算を適⽤すると, 射影した列データ全体に演算が適⽤される df[“総⼈⼝”] + 100
+100
データフレーム × 四則演算(2/2) # 各⾏の⽇本⼈⼈⼝の値をその⾏の総⼈⼝で割った値を返す 射影した列間の四則演算を適⽤すると, 各⾏の射影した列の値に対して演算が適⽤される df[“⽇本⼈⼈⼝”] / df[“総⼈⼝”]
新しい列の追加 # 各⾏の⽇本⼈⼈⼝の値をその⾏の総⼈⼝で割った値を返す 中括弧を⽤いて新しい列に代⼊演算をすることで 新しい列を追加することが可能 df[“⽇本⼈割合”] = df[“⽇本⼈⼈⼝”] / df[“総⼈⼝”]
# ドットアクセスでの代⼊はできない # df.⽇本⼈割合 = df[“⽇本⼈⼈⼝”] / df[“総⼈⼝”]
データフレーム情報へのアクセス(1/2) # データフーレムが変数df に格納されていると仮定 pandas.DataFrame.head df.head() データフレームの先頭数⾏を返すメソッド # データフーレムが変数df に格納されていると仮定
df.tail() データフレームの末尾数⾏を返すメソッド pandas.DataFrame.tail ← メソッドの引数に整数を与えるとその数だけ⾏を返す ← メソッドの引数に整数を与えるとその数だけ⾏を返す
データフレーム情報へのアクセス(2/2) # データフレームdfの(ゼロから始めて)2⾏⽬を抽出 df[2] ⾏番号を⽤いることで,データフレームの各⾏に アクセスすることが可能 # df の先頭⾏から10⾏⽬未満(9⾏⽬)までを取得 df[:10]
# df の2⾏から10⾏⽬未満(9⾏⽬)までを取得 df[2:10]
絞り込み(1/3) # 総⼈⼝の値が700万を超える⾏のみを抽出 中括弧の中で条件を指定すると,条件にマッチする ⾏を抽出したデータフレームが得られる df[df['総⼈⼝'] >= 7000000] # ドット表現を⽤いて条件を指定することも可能
# df[df.総⼈⼝ >= 7000000]
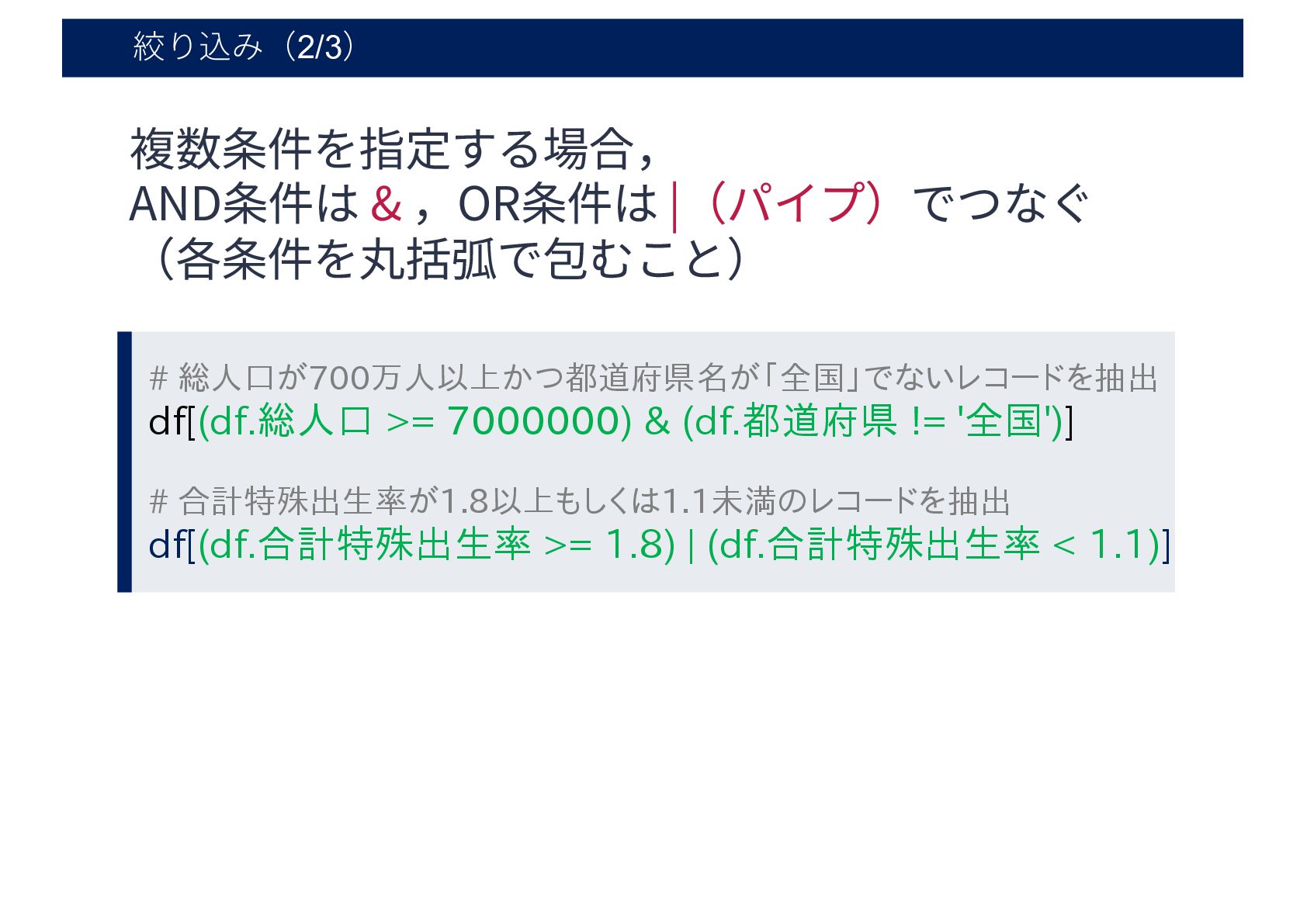
絞り込み(2/3) 複数条件を指定する場合, AND条件は & ,OR条件は |(パイプ)でつなぐ (各条件を丸括弧で包むこと) # 総人口が700万人以上かつ都道府県名が「全国」でないレコードを抽出 df[(df.総人口
>= 7000000) & (df.都道府県 != '全国')] # 合計特殊出生率が1.8以上もしくは1.1未満のレコードを抽出 df[(df.合計特殊出生率 >= 1.8) | (df.合計特殊出生率 < 1.1)]
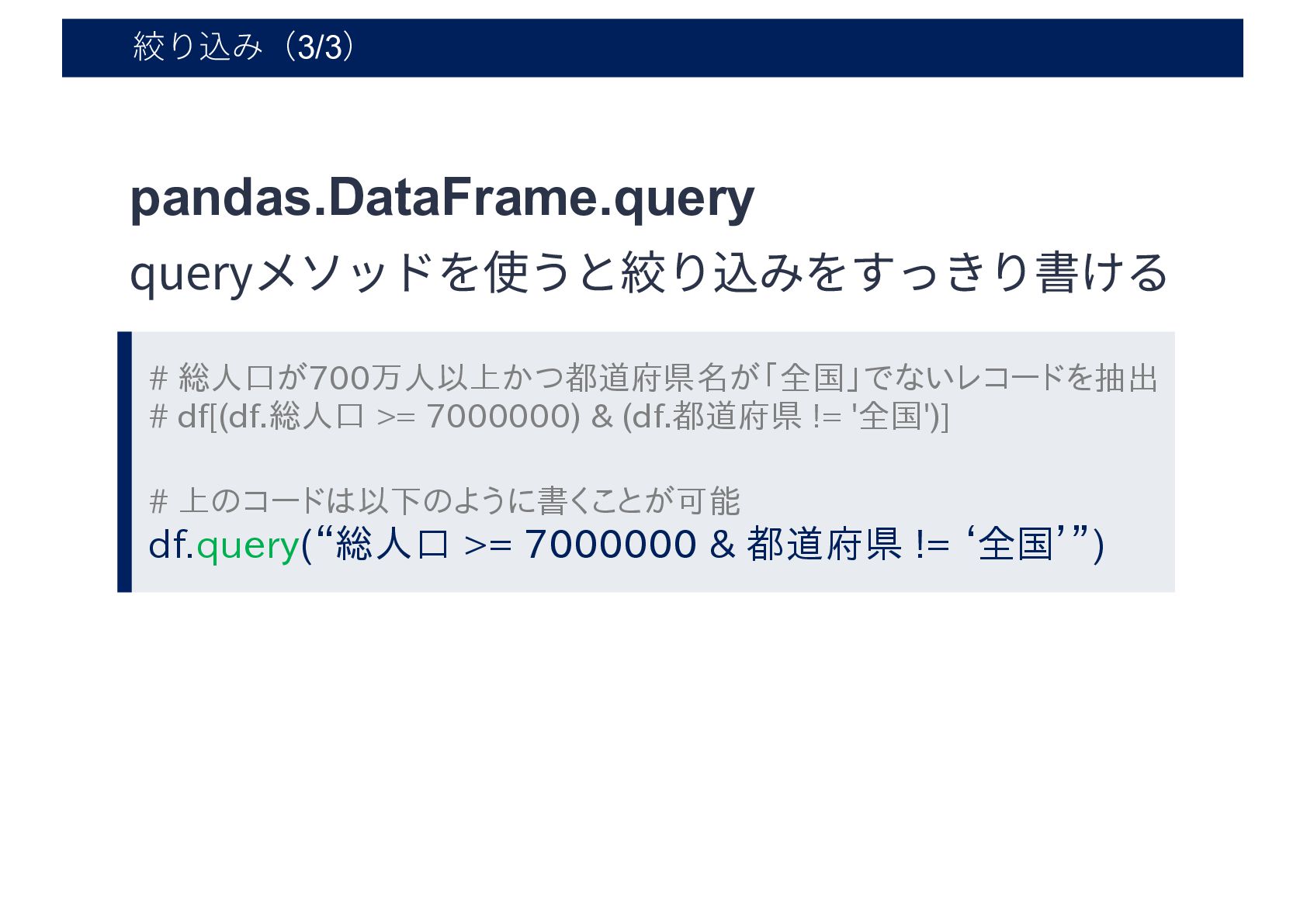
絞り込み(3/3) # 総人口が700万人以上かつ都道府県名が「全国」でないレコードを抽出 # df[(df.総人口 >= 7000000) & (df.都道府県 !=
'全国')] # 上のコードは以下のように書くことが可能 df.query(“総人口 >= 7000000 & 都道府県 != ‘全国’”) pandas.DataFrame.query queryメソッドを使うと絞り込みをすっきり書ける
データフレームの保存(1/2) df.to_csv( “保存先のファイル名”, sep=‘区切り文字’, header=True/False (デフォルトはTrue), index=True/False (デフォルトはTrue) ) pandas.DataFrame.to_csv
データフレームをCSV/TSVファイルに書き出す ↓⾒出し情報を書き出すか否か ↑インデックス情報を書き出すか
データフレームの保存(2/2) df.query(‘総人口 >= 7000000’).to_csv( “data/big-prefecture.tsv”, sep=‘区切り文字’, header=True, index=False ) pandas.DataFrame.to_csv
データフレームをCSV/TSVファイルに書き出す ←TSVファイルで書き出す ←インデックス情報(地域コード) はナシで書き出す
Hands-on タイム 以下のURLにアクセスして, ページ末尾のクイズを解いてみよう https://mlnote.hontolab.org/ 37
今後の予定 38 回 実施⽇ トピック 1 04/14 ガイダンス 2 04/21
pandas⼊⾨ 3 04/28 決定⽊からはじめる機械学習 4 05/12 クラスタリング1:k-means & 階層的クラスタリング 5 05/19 クラスタリング2:密度ベースクラスタリング 6 05/26 分類1:K近傍法 & 教師あり機械学習のお作法 7 06/02 分類2:サポートベクターマシン 8 06/09 分類3:ニューラルネットワーク⼊⾨
![pandas入門 ⼭本 祐輔 名古屋市⽴⼤学 データサイエンス研究科 [email protected] 第2回 機械学習発展(導入編) ⼭本祐輔 クリエイティブコモンズライセンス](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![射影(1/2) # データフーレムが変数df に格納されていると仮定 df.総⼈⼝ 表⽰したい列をドットもしくは中括弧で指定 df[“総⼈⼝”]](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_23.jpg){kind=link}
![射影(2/2) # データフーレムが変数df に格納されていると仮定 中括弧で列名リストを指定すると複数列を射影 df[“都道府県”, “総⼈⼝”]](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_24.jpg){kind=link}
![データフレーム × 四則演算(1/2) # 各⾏の総⼈⼝の値に100を加算 射影した列にスカラーの四則演算を適⽤すると, 射影した列データ全体に演算が適⽤される df[“総⼈⼝”] + 100](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_25.jpg){kind=link}
![データフレーム × 四則演算(2/2) # 各⾏の⽇本⼈⼈⼝の値をその⾏の総⼈⼝で割った値を返す 射影した列間の四則演算を適⽤すると, 各⾏の射影した列の値に対して演算が適⽤される df[“⽇本⼈⼈⼝”] / df[“総⼈⼝”]](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_26.jpg){kind=link}
![新しい列の追加 # 各⾏の⽇本⼈⼈⼝の値をその⾏の総⼈⼝で割った値を返す 中括弧を⽤いて新しい列に代⼊演算をすることで 新しい列を追加することが可能 df[“⽇本⼈割合”] = df[“⽇本⼈⼈⼝”] / df[“総⼈⼝”]](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_27.jpg){kind=link}
{kind=link}
![データフレーム情報へのアクセス(2/2) # データフレームdfの(ゼロから始めて)2⾏⽬を抽出 df[2] ⾏番号を⽤いることで,データフレームの各⾏に アクセスすることが可能 # df の先頭⾏から10⾏⽬未満(9⾏⽬)までを取得 df[:10]](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_29.jpg){kind=link}
![絞り込み(1/3) # 総⼈⼝の値が700万を超える⾏のみを抽出 中括弧の中で条件を指定すると,条件にマッチする ⾏を抽出したデータフレームが得られる df[df['総⼈⼝'] >= 7000000] # ドット表現を⽤いて条件を指定することも可能](https://files.speakerdeck.com/presentations/2b87f011838a4aa6a37519f1c930c72d/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}